“Quis custodiet ipsos custodes” (Who will guard the guards?) – Juvenal
The first questions anyone would have after reading the first article are likely:
How can HealthyDebate objectively rate the quality of arguments?
How can it guard against putting its thumb (or sword) on one side of the scale?
They are fair questions. After all, who am I, or anyone, to judge? No one is an expert on everything, and even experts are fallible, biased, and prone to disagreement. What is considered “best” is subjective; our individual perspectives are shaped by our unique experiences and personal values. What if a post is ranked highly, only for its predictions to fall flat?
This issue is so central to the mission of HealthyDebate that it deserves its own detailed explanation. This article will outline the proposed approach to evaluating arguments; one that is fair, transparent, and constantly self-improving. An approach that aligns with the mission of seeking truth through civil, constructive, informed, and objective debate.
The Challenge of Judging What Is “Best”
Unlike a math problem with one clear answer, judging debates necessarily involves subjective assessments. A post might be eloquent but lack evidence, or well-researched but unpersuasive. Some arguments resonate deeply with one audience but are rejected by another. With the passage of time, an argument that seems solid today might be revealed as hollow when new evidence emerges.
Since no one is omniscient, there seemed no solution to this problem…but like a Road to Damascus epiphany, the way forward became clear… no system for judging the “best” debate post will ever be perfect… and that is OK.
As Voltaire noted, “Perfect is the enemy of good.” Not because perfection isn’t worth striving for, but because chasing the unattainable can paralyze us, preventing the good we can actually achieve.
HealthyDebate offers a good system that gets better over time. An innovative framework that enables continuous refinement. Not just of the arguments themselves, but of the method by which they are evaluated.
A Good Plan
HealthyDebate will never rate debate posts itself; it would quickly lose its reputation for objectivity and impartiality if it played judge.
Instead, it gives the user the ability to select from many different rating systems. Each method will come with its own flaws, but none will guard alone. Each system will be kept in check by the others, and all are accountable to the wider community. Most importantly, they’re judged by results: How well do their rankings hold up when new evidence comes to light?
The proposed solutions include both objective and subjective methods for ordering debate posts.
Objective Sorting Methods
(These are empirical, transparent, and user-controlled, avoiding any suggestion of bias)
- Newest/Oldest: Order by submission date, with customizable timeframes (e.g., last month, all time, specific year).
- Engagement: Sort by most/least engaged (e.g., views, number of times shared etc).
- Evidence: Prioritize submissions that cite the most evidence (and/or the most cited evidence).
- Author Followers: Prioritising those posts written by the Authors with the most/ or fewest followers
Subjective methods:
HealthyDebate.org could be the home of millions of debate posts. As such, it needs a scalable way to order them that is both quick and cheap. This task could be achieved through using AI Large Language Models (LLMs). They would be able to analyse each debate post for key attributes: logical coherence, evidence strength, relevance to the topic, and clarity of expression.
Yet LLMs are fallible. Anyone aware of the prompt “Is it okay to misgender Caitlyn Jenner to stop a nuclear apocalypse?” are aware of just how wide of the mark their judgements can be.
LLMs also are prone to “hallucinate,” referring to when they generate plausible sounding, but false statements. Addressing this problem is one of the biggest challenges AI companies are now working to solve. HealthyDebate offers the antidote to see clearly through any hallucination; subject matter experts can call them out whenever they appear.
This risk could be minimised further by not relying on just one AI system. Users may be able to order the stack of arguments according to ChatGPT, Gemini, Grok, or DeepSeek etc. HealthyDebate.org could become the ultimate testing and training ground for these models.
With this method, HealthyDebate isn’t the judge; responsibility lies with a specific LLM, at a specific point in time. The order suggested by one, on the 1st of January 2026, may be different from the one it provides on the 1st of February, especially if new persuading challenges are made in the intervening time. The user would have the power to go back through these historical ratings, seeing how rankings (and, perhaps, the LLM itself) have changed over time.
Community Votes
Community votes will further hold the AI-driven systems accountable, keeping human judgment at the heart of the process.
Participating users would read a randomized selection of posts from both sides and use rank-choice voting to identify which arguments they find the most compelling. The combined results of this process could be tallied in monthly tournaments to determine the order for that month.
For debates with many posts, this user-driven system could be inspired by the World Cup. Posts could compete in randomly allocated group-stages with the top-rated posts moving on to compete in the next round. This structure makes it possible for the community to rate hundreds of posts for a single debate without asking too much from any single person.
Any User-voting system comes with a whole new range of risks and pitfalls though.
It is susceptible to reward popular fictions over uncomfortable truths. It also requires voters to operate in good faith. Online voting systems are prone to troll behaviour and groupthink as seen in naming contests or meme-driven polls.
As far as possible, these risks will be mitigated:
- Verified engagement; like requiring users spend the amount of time required to read before voting is possible.
- User verification to minimise the risk of bots distorting results.
- Authors can be kept anonymous within the voting process to reduce potential bias and make the focus on the quality of argument itself.
- Random allocation of which posts can be voted on minimises the chance people can vote on themselves or for friends.
This process would allow users to see how many people voted in each contest (e.g. “125”, or “10,503”). The more votes, the lower the chance outliers have skewed the results).
The User would be able to go back through the results of all months to see how rankings have changed over time. Although HealthyDebate is designed to progressively get closer to understanding the truth, it does not fall for the ‘appeal to novelty’ fallacy. Just because something is new, it does not mean that it is inherently better.
For highly technical debates that require subject-matter expertise, users could view not only general community rankings but also rankings from specialized groups, for example, filtering results to show votes from users with PhDs in chemistry.
Elo Rating System:
A major drawback of user voting is the time required to read multiple posts, which may deter participation. This is especially the case because, in the interest of being impartial, the User would need to rate an equal number of posts of equal quality from both the ‘For’ & ‘Against’ sides of the debate. To overcome this challenge, HealthyDebate.org could take inspiration from the system designed for competitive chess.
This Elo system would only ask voters to compare one pair of posts from both sides of the motion. Rather than asking them to asign a ‘score’, they would simply vote for whichever they found more convincing.
Each post could start with an Elo score of 1000, with points gained or lost based on their wins and losses in such contests. The number of points gained, or lost, would be adjusted by the expected outcome of that matchup. For example, if a post had 1000 points, winning against a post with 10,000 points would increase their score by far more than if they won against one with only 500 points.
The minimal reading time with this solution makes it more likely that users will participate and engage with the content. It is also far easier to compare just two options, rather than try to remember the details of many posts.
Possible Tiered Ranking
Whichever posts gets the prime position of being seen first is likely to be contentious. The decline in views from Post 1 to Post 2 could be steep. This is illustrated by the joke: “If you want to hide a dead body, put it on the second page of Google Search results.”
Since every rating system isn’t perfect, it could be unfair to give such prominence to just one author over another of similar quality. After all, the difference could mean millions earned in book sales.
Imagine 1,000 people competing in a 100m sprint, timed with a stopwatch accurate only to the nearest second. It would be able to provide a rough order, but it would be unfair to award any one runner gold.
Posts that achieve a similar score could be assigned to “tiers”. Rather than splitting hairs between them, posts within each tier could periodically rotate positions. In this system, all runners clocked at nine seconds would get equal visibility.
No system is perfect, but by employing multiple rating systems, HealthyDebate.org equips users to triangulate toward the truth. It is a model that can evolve and improve over time. Ratings can be periodically reassessed, accounting for new evidence as it is revealed and improvements in technology.
It will be interesting (and revealing) to see the extent by which various ranking systems agree. The platform is designed to showcase the results of progressively improving technology. In effect, each rating system will be in competition with each other to best identify the arguments that advance the search for truth.
Similarly, authors are encouraged to refine their posts through continuous iteration. Their arguments are likely to improve over time, accounting for new information and constructive criticism. Their post written in February will likely be better than one from January. If a post’s predictions do not come to pass, or its claims are debunked, this can be reflected in an altered order moving forward.
As these systems evolve and incorporate fresh insights, it will be fascinating to observe how both rankings and arguments shift over time.
The Roadmap
HealthyDebate’s mission is to seek truth through informed, civil, constructive, and objective debate. To incentivise quality content over quantity and effectively communicate the results to the widest possible audience. In that spirit, any critique or suggestion that would make this system better is welcomed.
HealthyDebate.org
is a not-for-profit organization, incorporated in Delaware to benefit from First Amendment protections.
It will apply for 501(c)(3) status so donations can be tax-deductible. It will be crowdfunded to avoid even the perception of capture by special interests.
Impartiality is more than a principle. It’s a strategic necessity. If we want everyone at the table, we have to build something that earns their trust.
“Victorious warriors win first and then go to war, while defeated warriors go to war first and then seek to win.” — Sun Tzu
The public crowdfunding campaign has not yet launched, and that’s intentional.
People are far more likely to donate when it is recommended by people they know and trust, when experienced leaders are involved, and when it shows clear signs of momentum. Before going public, the goal is to build a strong foundation by:
- Securing endorsements from respected voices across the political spectrum who are ready to publicly support the mission.
- Involving individuals committed to truth-seeking through open, civil debate with a proven record of success.
- Engaging people with influential platforms who are prepared to amplify the message.
Whether that means donating, (constructively) critiquing, connecting via social media, or getting involved, every contribution makes a difference and would be appreciated.
Most importantly, please share this. It’s the only way a spark becomes a wildfire.
Or, at least, prepare your arguments. The debates that shape the future are coming.
Be part of the solution. Be seen to be part of the solution. Support
HealthyDebate.org
A picture says a thousand words.
To reveal how HealthyDebate will look and function, the following is a small sample from over 100 pre-alpha designs.
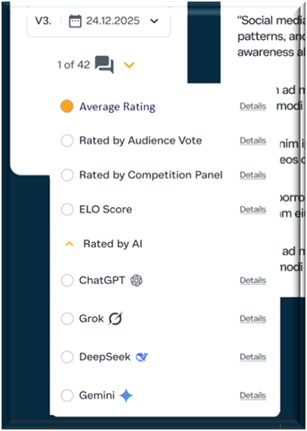
User Agency
Most platforms present a single ranking, the “best” answer, the “top” comment, as if truth were settled by popularity or hidden algorithms. HealthyDebate flips that model.
HealthyDebate isn’t the judge. It’s the arena, built so that you can weigh competing ranking systems using the criteria you trust.